Abstract
We introduce LUMOS, a language-conditioned multi-task imitation learning framework for robotics. LUMOS learns skills by practicing them over many long-horizon rollouts in the latent space of a learned world model and transfers these skills zero-shot to a real robot. By learning on-policy in the latent space of the learned world model, our algorithm mitigates policy-induced distribution shift which most offline imitation learning methods suffer from. LUMOS learns from unstructured play data with fewer than 1% hindsight language annotations but is steerable with language commands at test time. We achieve this coherent long-horizon performance by combining latent planning with both image- and language-based hindsight goal relabeling during training, and by optimizing an intrinsic reward defined in the latent space of the world model over multiple time steps, effectively reducing covariate shift. In experiments on the difficult long-horizon CALVIN benchmark, LUMOS outperforms prior learning-based methods with comparable approaches on chained multi-task evaluations. To the best of our knowledge, we are the first to learn a language-conditioned continuous visuomotor control for a real-world robot within an offline world model.
Approach
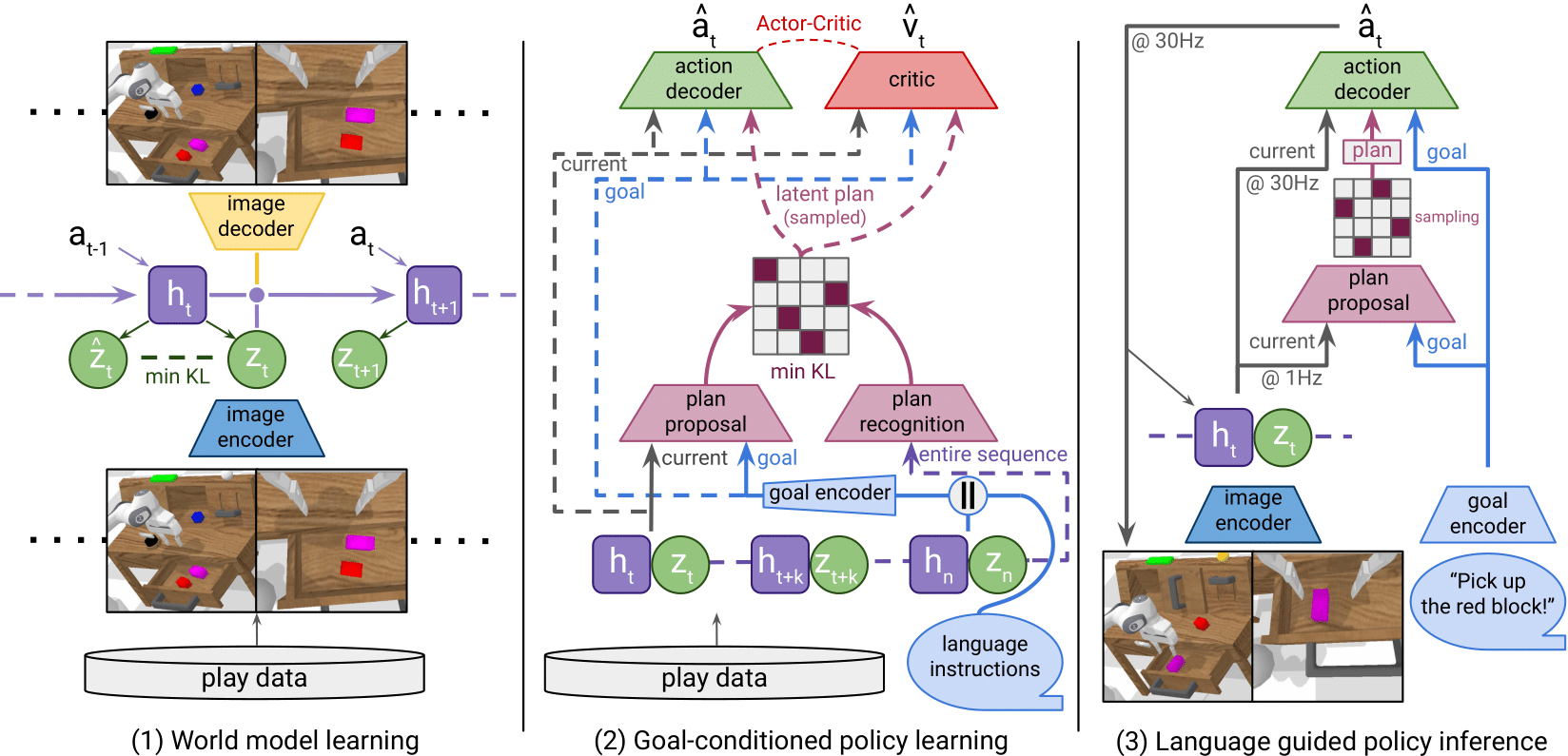
Training consists of two phases:
1. A world model is learned from the unlabeled play dataset.
2. An actor-critic agent is trained within this learned world model to acquire a goal-conditioned policy
by guiding imagined sequences of latent model states to match the latent trajectory of the expert
demonstrations.
During inference, the language-conditioned policy, trained entirely in the latent space of the world
model, successfully transfers to the real environment.
Experiments
In the real-world experiment, we test LUMOS on real-world robotic tasks using a Franka Emika Panda arm
in a 3D tabletop environment. The goal is to evaluate how well the robot understands and executes object
manipulation tasks based on language instructions.
We collected a three-hour dataset by teleoperating the robot with a VR controller, guiding it through
interactions with objects like a stove, a bowl, a cabinet, a carrot, and an eggplant. The robot's
movements were recorded using RGB cameras, and only a small fraction of the data (less than 1%) was
annotated with language descriptions.
We evaluated LUMOS’ ability to complete five-step instruction sequences, measuring how well it followed language commands on multi-stage long-horizon manipulation tasks.
The robot successfully follows instructions and completes multi-step tasks, showing adaptability and error recovery. Performance varies with task complexity, indicating that more training data could enhance robustness, bringing us closer to more advanced, language-guided robotic assistants.
Dataset
Our real-world play dataset is licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. If you use the data in an academic context, please consider citing our paper.

Code
The source code for this project is available on our GitHub repository for academic usage and is released under the MIT license.
Publications
LUMOS: Language-Conditioned Imitation Learning with World Models Iman Nematollahi, Branton DeMoss, Akshay L Chandra, Nick Hawes, Wolfram Burgard, Ingmar Posner Pdf
BibTeX citation
@inproceedings{nematollahi25icra,
author = {Iman Nematollahi and Branton DeMoss and Akshay L Chandra and Nick Hawes and Wolfram Burgard and Ingmar Posner},
title = {LUMOS: Language-Conditioned Imitation Learning with World Models},
booktitle = {Proceedings of the IEEE International Conference on Robotics and Automation (ICRA)},
year = {2025},
url={http://ais.informatik.uni-freiburg.de/publications/papers/nematollahi25icra.pdf},
address = {Atlanta, USA}
}





